Neo4jについてちょちょいと調べたまとめ
by Yuji Yamamoto on June 8, 2014
Neo4jについて、Eightでも使えないかな、なんて考えつつ調べていました。
なので本日はそれについて備忘録的なのを。
なお、調べた時点のNeo4jのバージョンは2.0です。
そしてこの文章はNeo4jを実際に使ってみた感想ではなく、
ちょちょっと本やブログ記事などを読んで得た程度の知識である点をご了承ください。
そもそもNeo4jって?
「property graph」というデータモデルを採用した、GraphDBの一種です。
この分野では最も有名なものとして知られている模様です。
ひとまず、このへんの用語のお話は、参考にした下記のサイトや電子書籍にお任せします。
- 「GraphDB徹底入門」〜構造や仕組み理解から使いどころ・種々のGraphDBの比較まで幅広く〜
- GraphDBについて - Kompira開発者ブログ
- Graph Databases
- 2.1. What is a Graph Database? - - The Neo4j Manual v2.0.3
追記: 最近Graph Databasesの日本語版が出ましたね。 せっかくなんでアフィリエイトのタグでも載せておきましょうか。
グラフデータベース ―Neo4jによるグラフデータモデルとグラフデータベース入門
速さの秘密について
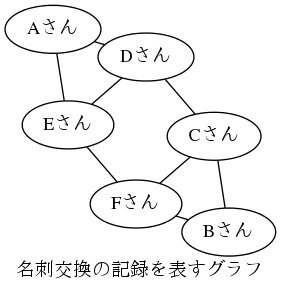
Neo4jの人気の理由をまず一つ挙げるならば、 グラフ構造でデータを保存した場合の、探索効率の高さでしょう。 例えば下記のようなグラフにおいて、 「『Aさんと直接名刺交換した人』と名刺交換した人のうち、まだAさんと名刺交換してない人」 みたいな問い合わせに回答するときに、 RDBをはるかに凌ぐようなパフォーマンスを出すことができます。

SVGの画像ですので、閲覧できない場合はこちらのPNG版をご覧ください。
具体的にどう速いのかというと、 上記のような問い合わせにおいて、「Aさんと名刺交換した人」を求めるのに、 RDBですと「テーブル全体のレコード数の対数(log(n))」に対して比例した時間がかかる1 のに対して、 Neo4j(あるいは似たデータ構造を持つGraphDB)だと、 「Aさんと直接名刺交換した人の数」に比例した時間のみがかかります。 一般に、テーブル全体のレコード数(この場合、名刺交換をした人々を表すレコードの数)は、 個々のレコードにつながるレコード数(この場合、ある人と直接名刺交換した人の数) よりも圧倒的に多いため、 後者にしか影響を受けないNeo4jの探索は、速いのです。 とりわけ、「Aさんと名刺交換した人と名刺交換した人」のような、 二次、三次のつながりをたどる場合、 RDBの場合はつながりの数だけインデックスを1から辿らなくてはならないため、 更にその差は大きくなります。
index-free adjacency
なぜこのような、「個々のレコードにつながるレコード数」のみに影響を受ける探索ができるのでしょう? その秘密は、やはりデータ構造にあり、 「index-free adjacency」という性質がキーとなっています2。
「index-free adjacency」とは何でしょうか。 当記事の主な情報源となった、 そのものずばり「Graph Databases」のp.145によれば、 「index-free adjacency」な特性を持つNeo4jでは、 各ノード・リレーションは、固定長のレコードとして保存され、 レコードの中に、直接隣接しているノード、またはリレーションへの、 物理的なアドレスを記録しているのです。 「物理的なアドレス」とはどういうことでしょう? 例えば、1レコードの長さが9バイト3だとして、 「物理的なアドレス」が「100」のレコードがあったとすると、 そのレコードはファイルの先頭から数えて、ちょうど900バイト目にあることとなります。 このレコードを参照するには、ファイルの先頭から900バイト目までseekするだけでよい、 ということになるので、仮にキャッシュにヒットせず、 ファイルからノード・リレーションを読み込んだとしても、幾分参照が楽になるのです。
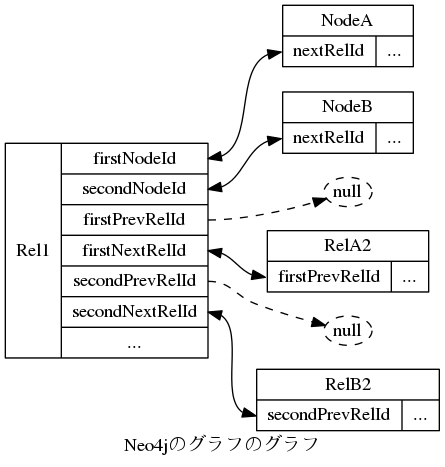
ここまで読んだ方の中には、 「ちょっと待てよ、Neo4jのノードは複数のリレーションを持つことができるんだろ? どうやって固定長のレコードの中に複数のリレーションへのアドレスを詰め込むんだ?」 と疑問に思う方もいらっしゃるかもしれません。 その理由は、まぁ、ある程度データ構造について知識がある方はすぐに察しがつくでしょう、 リンクリストになっているからです。 このことをもう少し詳しく説明するために、 ノードを表すレコード(ノードレコード)とリレーションを表すレコード(リレーションレコード)が、 どのように互いの物理的なアドレスを参照しあっているか、図にしてみましょう。 Neo4jのグラフを表すグラフです4。

SVGの画像ですので、閲覧できない場合はこちらのPNG版をご覧ください。
上記のグラフでは、例えばRel1のfirstNodeIdとNodeAのnextRelIdとの間にある矢印は、
NodeAとRel1の相互参照関係を表します。
ご覧の通り、1個のノードレコード(NodeA, NodeB)は、
自分が持っている最初のリレーションレコード(Rel1)へのアドレス(nextRelId)しか持っていません。
そしてノードが持つその他のリレーションへのアドレスは、
「最初のリレーション」が持つ、
firstNextRelId、またはsecondNextRelIdというプロパティで参照しているのです。
これらは名前から察せられる通り、
それぞれリレーションにつながる「片方のノードが持つ次のリレーション」と、
「もう片方のノードが持つ次のリレーション」を表します。
こうしたつながりを続けて1つずつ参照するため、
Neo4jの探索は
「個々のノードにつながるリレーションの数」のみに比例した時間で実行できるのです。
遅さの秘密について
このように優れた特性を持つNeo4jですが、 この「index-free adjacency」という性質のせいで、却って著しく遅くなってしまうケースがあります。 「index-free adjacency」は「速さの秘密」であるとともに、「遅さの秘密」でもあるのです。 そうしたケースを、CyberAgentの松本陽介さんが書いた論文が示してくれました。 松本陽介さんによれば、ノードにつながるリレーションの数が、 1万以上まで達すると、探索が非常に遅くなってしまい、使いものにならなくなってしまうそうです。 そのため、Amebaのような、 一人のユーザーがつながる数が10万以上まで達することがある大規模なサービスでは、 採用は難しいとのことです。
先ほど説明した、 「個々のノードにつながるリレーションの数に比例した時間での探索」 という特徴から、冷静に考えてみれば、これは当たり前の問題です。 どうやらNeo4j(と、その他同様のデータモデルを持つGraphDB)には、 グラフを扱うデータベースでありながら、 巨大なグラフを扱う上で致命的な問題を抱えているようです。 ぱっと見いかにも向いていそうな、 TwitterやFacebookなどが採用しないのにも、恐らくこうした背景があるのでしょう。
拡張性について
「GraphDB」という性格上、また、固定長のレコードでアドレスを管理している性格上、 Neo4jには他にも拡張性に関する制限があります。
Capacity
前述した、リレーションレコードやノードレコードが持つ、 他のノードやリレーションに対する物理的なアドレスは、数値の大きさに上限があります。 これは各レコードが固定長のレコードであることを考えれば当然のことで、 このことが必然的に、一つのデータベースで保存できるノードやリレーションの数にも制限を与えます。 その最大数は、 ノードとリレーションそれぞれ235(約340億)個まで と決まっています。
しかしながら言うまでもなく、こうした制限はRDBを始め、他のDBMSにも存在します。 仮にMySQL(だけじゃなく他の大抵のRDBがそうですよね?)の符号なしBIGINTを レコードの主キーとして使った場合、 その最大値は264(約1800京) と決まっていますので、その場合、一つのテーブルに保存できるレコードの数は、その値までです。 もちろんRDBは他のデータ型も主キーにすることができるため、単純な比較はできませんが、 RDBがデータベース内の複数のテーブルに対してこの個数分のレコードを保存できるのに対して、 Neo4jがデータベース全体でこの個数分のノード・リレーションを保存しなければならないことを思えば、 Neo4jが保存できるデータの量は、RDBよりもかなり少なそうです5。 そう頻繁にはないと思いますが、 極めて多くの個数のデータを書き込む可能性があるアプリケーションでは、 この点をちょっと考慮したほうが良いかもしれません。
Sharding
Neo4jを始めGraphDBはその構造上、
例えばMySQL Spiderやその他のNoSQL系DBMSが行うような、
レコードを保存するサーバーを分散させる、という意味でのシャーディングはできません。
代わりに、Neo4jは、有料版の機能である、
「Neo4j High Availability (Neo4j HA)」という機能を利用して、
サーバーのメモリ上のキャッシュを分散させることができます。
Neo4j HAとは、いわゆるマスター・スレーブ方式のレプリケーションを実現するための機能です。
ノードやリレーションが、1個のサーバーではメモリにキャッシュしきれなくなった時、
この機能の設定を変えることで、特定のパラメーターの値ごとに、
キャッシュするノードやリレーションを、複数のサーバーに分配させることができます。
しかしながらこれは、主に読み取り性能をスケールさせるための機能であり、
やはり大量の書き込みを処理する必要があるアプリケーションにはあまりメリットがないでしょう。
とは言え、ドキュメントを見る限り、
ロードバランサーの設定を変えるだけで自動的に分散させていってくれるそうなので、
読み取り性能に関しては、大変お手軽に、
しかもレプリケーションの旨味である高い可用性を維持したまま、拡張できそうです6。
トランザクションの仕様について
Neo4j HAの話と少し関連して、Neo4jのトランザクションの仕様についても述べておきましょう。 「Neo4jはNoSQLだ」なんて聞くと、MongoDBやRiakなど他のNoSQLのように、 「なんだ、じゃぁトランザクションは使えないのか」なんて思われる方もいらっしゃるかもしれません。 しかしながら、トランザクション機能の有無は NoSQL(と言うより非関係モデル)のデータベースに本質的なことではなく、 NoSQLなデータベースの中にも、ACID準拠なトランザクションを使えるものはあります。 もちろん、Neo4jはトランザクション機能を持っています。
Neo4jのトランザクションは、恐らく概ね各種RDBMSと似ているのでしょう。
デフォルトの独立性レベル(isolation level)はREAD_COMMITEDと同等です。
すなわち、読み込みだけではレコードを一切ロックしないため、
同じ内容のレコードを読み込むクエリを、一つのトランザクション内で2回以上発行した場合でも、
違う結果が返る恐れがあります。
1回めのクエリで読み込んでから2回めのクエリを発行するまでの間に、
他のトランザクションによって、対象のレコードが更新されている可能性があるからです。
もちろん、お気に召さないのであれば、SERIALIZABLEなどの、
別の独立性レベルに切り替えることもできます。
それから、ロックはデータベース全体ではなく、
処理するノード・リレーション単位で取得することができます。
Neo4j HA、すなわちレプリケーションを使用した場合のトランザクションの振る舞いは、 ちょっと変わっています。 それは、マスターノードだけでなく、スレーブノードにも、書き込みを行える、という点です。 マスター、スレーブ、それぞれに対してトランザクション中に書き込み要求を行った場合の振る舞いの違いは、 下記のとおりです。
- マスターノードの場合、
クライアントからの書き込み要求を受けた際、マスター自身の更新が終わった後、
適用した更新を、
ha.tx_push_factorという項目で設定した数(デフォルトで1)のスレーブに、 楽観的に適用しようと試みます。 「楽観的に」というのは、ここで何らかの理由で、スレーブへの更新の適用が失敗したとしても、 ひとまずトランザクション全体は「成功した」ということにする、という意味です。 更新しそこねたスレーブや、残りのスレーブはどうするのかというと、 (そのままダウンしたりしていない限りは)ha.pull_intervalという項目で設定した時間おきに、 各々がマスターからまだ適用していない更新がないか尋ね、それぞれ適用します。 つまり、マスターノードへの書き込みはすぐに反映されるものの、 スレーブノードへの書き込みは、遅れて少しずつ反映されるのです。 - スレーブノードの場合、 クライアントからの書き込み要求を受けた際、 最初にマスターに問い合わせ、まだ自分に適用していない更新がないか尋ね、マスターと同期します。 そして同期できてから初めて、書き込み要求を先にマスターに適用し、 それが成功してやっと、自分自身に書き込みます。 これらの処理がクライアントに制御を返すまで行われるため、 通常スレーブへの書き込み要求は、マスターへの書き込み要求に比べ、はるかに遅く処理されます。 そのため「Graph Databases」のp.79によれば、 現在この方法は推奨されていないそうです。 唯一使う時があるとすれば、 前述のキャッシュによるシャーディングを行っている場合に、 クライアントが自分のトランザクションで書き込んだデータを、 同じトランザクション中に読み込みたい場合だろう、とのことです。
おわりに
Neo4jについて取り上げたい特徴は、まだまだあります。
それらを一言で言うなら、
GraphDBという構造ならではの柔軟性や、Cypherというクエリ言語のわかりやすさ、
加えてJVMベースの言語でサーバー自体を簡単に拡張できる点、といったところでしょうか。
最初の2点については、本稿の参考文献含めその他のウェブサイトや、
手前味噌ですが私がプリキュア Advent Calendarというアレなイベントで書いた記事が、
ひょっとしたら参考になるかもしれません。
3つめについては、
私が知るかぎりNeo4jの公式ドキュメントぐらいしか詳しい情報がありませんでした。
それから、Neo4jについて、今回分からなかった、 個人的に気になる部分をメモしておきます。
- 実際にデータを一定量蓄積した後の、スキーマの変更しやすさ。
Neo4jはMongoDB等と同様、仕組みの上ではスキーマレスですが、 実際にアプリケーションを作る上では、結果的に必ず型を設計することになるはずです。 型なくしては、人間はデータを分類し、 規則に従って処理するプログラムを書けなくなってしまうでしょうから。 そしてそれを変えたくなる日もまた、必ず来ることになるでしょう。
一般にスキーマレスなデータベースは、RDBMSと比べて型を変えやすいとは聞きます。 とは言え、例えば単純な例として、リリース後まで見逃してしまった手強いプロパティ名のtypoを、 みっともないからと言って正したくなったとしましょう。
仮にtypoしてしまったノードが数千個程度存在していたとして、 果たして直すのにどれぐらいの時間がかかるでしょうか?
この点は他のNoSQL系DBMSでも問題になりそうなので、比較するのも面白そうです。 - 実際の使用感(安定性とか、速度とか、アプリケーションの作りやすさとか)。
特に、これまでだったら無難にRDBMSを選びそうな場面で、どの程度代わりに使えるか。
私が普段趣味で作るもののことを思うと、なかなか機会がなさそうですし、 ましてや大容量なデータとなると、私の個人の努力では試しづらそうではありますが…。
最後に、ここまでNeo4jについて調べての、個人的な印象を述べておきます。
Neo4jは、表現力の高さと高速さ、そしてACIDなトランザクションを備えた、
いいことづくめのDBMSだと思ってきました。
しかしながら、ここまで述べましたとおり拡張性に問題があり、
それこそFacebookやTwitter、CyberAgentのように、本当にビッグなサービスを作りたいのであれば、
メインのデータベースとして選ぶのには難があるようです
(もちろん、実際にそれぐらいビッグにできるかは別問題として)。
Eightも当然それぐらいの領域を目指したいと、
私も会社も考えているはずですので、
そんな限界に達するかも知れないというリスクを払ってまで、無理に移行する必要はないでしょう。
とは言え、RDBMSほどではないとはいえ、すでに多くの採用事例があるようですし、
何らかのサブシステムとして採用する価値はありそうです。
他のグラフ演算エンジンも視野に入れつつ、もう少し探求してみるのも面白そうです。
また、今後趣味でちょっとしたデータベースアプリケーションを作る際、
Neo4jのお陰で、設計が楽しくなりそうなのがいいですね。
もちろん、2分木によるインデックスを利用していた場合の話です。↩︎
日本語に訳すなら、「インデックスなし隣接性」か、 はたまたそのまま「インデックスフリー隣接性」とカタカナ語をもっと駆使するのがよいでしょうか。 いずれにしても、「アドジェイスンシー」という単語はカタカナ語としては発音しにくすぎです。↩︎
Graph Databasesのp.145に載っていた、 Neo4jのノードレコードの長さです。 ただし同書で取り上げられたノードレコードには、Neo4j 2.0からできた、 ノードのラベルについての情報がありません。恐らく1.9でのお話なのでしょう。↩︎
ここでは、 ノードやリレーションのプロパティを表すレコードについては割愛させていただきます。 詳細は前述の「Graph Databases」のp.144をご覧ください。 電子版が無料でダウンロードできます。↩︎
ただし、Neo4jは削除したノード・リレーションのID、 すなわち前述の物理的なアドレスを、適宜自動的に再利用します。 ここまで述べた制限を考慮しての設計なのでしょう。↩︎
よーく考えてみたら、 MySQLのレプリケーションでもほとんど同じことができそうな気がしてきましたが、 当方あまり詳しくないので、どうかご容赦ください。↩︎

{kind=link}
{kind=link}